> ## Documentation Index
> Fetch the complete documentation index at: https://docs.idun-group.com/llms.txt
> Use this file to discover all available pages before exploring further.
# How to deploy a LangGraph agent to production in 5 minutes
> Step-by-step tutorial to take a LangGraph agent from a local script to a production API with streaming, guardrails, memory, and observability using Idun Engine.
You built a LangGraph agent that works in a notebook. Now you need it behind an API with authentication, conversation memory, guardrails, and tracing. This guide takes you from a working `StateGraph` to a production endpoint in under 5 minutes.
## The production gap
LangGraph gives you a graph-based runtime for building agents. It does not give you the infrastructure to serve them. When you move from `graph.invoke()` in a script to handling real traffic, you run into five missing pieces:
No built-in HTTP server. You write FastAPI routes, CORS, request parsing, and streaming yourself. LangServe is deprecated. LangGraph Platform requires a LangSmith account.
LangGraph supports checkpointers, but you wire up database connections, async lifecycle, and thread ID routing from HTTP requests yourself.
Your agent will process PII, jailbreak attempts, and toxic content unless you build input/output validation from scratch.
When a production agent returns garbage at 3am, you need traces. LangGraph has no built-in tracing. You instrument it yourself.
And one more: **no streaming protocol.** Modern chat UIs expect Server-Sent Events with structured events (text deltas, tool calls, thinking indicators). LangGraph emits raw `astream_events` that you need to map to a protocol your frontend understands.
Idun Engine fills all five gaps. Your `StateGraph` stays unchanged. Idun wraps it into a FastAPI service with AG-UI streaming, configurable memory, guardrails, and multi-provider observability, all configured through a single YAML file.
This guide drives configuration from `config.yaml`. The standalone runtime exposes the same fields through the admin panel at `/admin/`, so any step that edits the YAML can also be done from a browser; the DB is the source of truth in steady state.
## What you will build
A LangGraph agent served as a REST + AG-UI streaming endpoint.
In-memory persistence, upgradeable to PostgreSQL or SQLite.
PII detection that blocks requests before they reach the agent.
Langfuse tracing on every invocation with full LLM call details.
## Prerequisites
* Python 3.12+
* A Gemini API key (or any LangChain-compatible LLM)
* 5 minutes
Create a project directory with an agent that has tool calling built in:
```bash theme={"theme":{"light":"github-light","dark":"github-dark"}}
mkdir langgraph-prod && cd langgraph-prod
mkdir agent && touch agent/__init__.py
```
```python agent/agent.py theme={"theme":{"light":"github-light","dark":"github-dark"}}
import os
from langchain_core.tools import tool
from langchain_google_genai import ChatGoogleGenerativeAI
from langgraph.graph import MessagesState, START, StateGraph
from langgraph.prebuilt import tools_condition
@tool
def add(a: float, b: float) -> float:
"""Add two numbers together."""
return a + b
@tool
def multiply(a: float, b: float) -> float:
"""Multiply two numbers together."""
return a * b
model = ChatGoogleGenerativeAI(
model="gemini-2.5-flash",
google_api_key=os.getenv("GEMINI_API_KEY"),
)
tools = [add, multiply]
async def call_model(state: MessagesState):
model_with_tools = model.bind_tools(tools)
response = await model_with_tools.ainvoke(state["messages"])
return {"messages": [response]}
async def call_tools(state: MessagesState):
from langchain_core.messages import ToolMessage
tools_by_name = {t.name: t for t in tools}
last_message = state["messages"][-1]
results = []
for tool_call in last_message.tool_calls:
t = tools_by_name[tool_call["name"]]
result = await t.ainvoke(tool_call["args"])
results.append(
ToolMessage(
content=str(result),
tool_call_id=tool_call["id"],
name=tool_call["name"],
)
)
return {"messages": results}
workflow = StateGraph(MessagesState)
workflow.add_node("call_model", call_model)
workflow.add_node("tools", call_tools)
workflow.add_edge(START, "call_model")
workflow.add_conditional_edges("call_model", tools_condition)
workflow.add_edge("tools", "call_model")
```
Two things matter here:
1. The variable `workflow` is an **uncompiled** `StateGraph`. Do not call `.compile()`. Idun compiles it for you with the configured checkpointer and store.
2. The state uses `MessagesState` (a `TypedDict` with a single `messages` field). Idun auto-detects this as a chat-mode agent. If your state has additional fields, Idun treats it as a structured-input agent and exposes the full JSON Schema through the capabilities endpoint.
Install the engine wheel (it bundles the standalone admin/chat/traces app and the `idun` console script):
```bash theme={"theme":{"light":"github-light","dark":"github-dark"}}
pip install idun-agent-engine langchain-google-genai
```
Create `config.yaml` next to your agent directory:
```yaml config.yaml theme={"theme":{"light":"github-light","dark":"github-dark"}}
agent:
type: LANGGRAPH
config:
name: "Production Chatbot"
graph_definition: "./agent/agent.py:workflow"
checkpointer:
type: memory
```
That is a complete, valid config. Three fields define your entire setup:
* `type: LANGGRAPH` tells Idun which adapter to use.
* `graph_definition: "./agent/agent.py:workflow"` points to your file and variable. Format: `path/to/file.py:variable_name`. Idun dynamically imports it.
* `checkpointer.type: memory` enables in-memory conversation persistence. Every request with the same `thread_id` continues the conversation.
Start the server:
```bash theme={"theme":{"light":"github-light","dark":"github-dark"}}
export GEMINI_API_KEY="AIzaSy-replace-with-your-gemini-key"
idun serve
```
You should see:
```
Agent 'Production Chatbot' initialized and ready to serve!
Starting Idun Agent Engine server on http://localhost:8000...
```
Your agent is now live. Open `http://localhost:8000/docs` to see the full OpenAPI spec, `http://localhost:8000/` for the chat UI, and `http://localhost:8000/admin/` for the admin panel. To use a different port, export `IDUN_PORT` before running `idun serve`.
The canonical endpoint is `POST /agent/run`, which implements the AG-UI streaming protocol used by CopilotKit, Vercel AI SDK, and other modern chat frontends.
```bash theme={"theme":{"light":"github-light","dark":"github-dark"}}
curl -N -X POST http://localhost:8000/agent/run \
-H "Content-Type: application/json" \
-H "Accept: text/event-stream" \
-d '{
"threadId": "session-1",
"runId": "run-1",
"state": {},
"messages": [
{"id": "msg-1", "role": "user", "content": "What is 25 multiplied by 17?"}
],
"tools": [],
"context": [],
"forwardedProps": {}
}'
```
You get back a stream of AG-UI events: `RunStarted`, `TextMessageStart`, `ToolCallStart`, `ToolCallEnd`, `TextMessageContent` (with deltas), `TextMessageEnd`, `RunFinished`. Your frontend renders these as they arrive.
You can also check capabilities and health:
```bash theme={"theme":{"light":"github-light","dark":"github-dark"}}
curl http://localhost:8000/agent/capabilities
curl http://localhost:8000/health
```
Or open `/` in a browser and chat with the agent directly through the bundled chat UI.
Guardrails validate input and output at the API boundary. They run before and after your agent, blocking requests that violate your policies. Idun uses [Guardrails AI](https://guardrailsai.com) validators, downloaded and run locally.
Add a `guardrails` section to your `config.yaml`:
```yaml config.yaml theme={"theme":{"light":"github-light","dark":"github-dark"}}
agent:
type: LANGGRAPH
config:
name: "Production Chatbot"
graph_definition: "./agent/agent.py:workflow"
checkpointer:
type: memory
guardrails:
input:
- config_id: detect_pii
pii_entities: ["EMAIL_ADDRESS", "PHONE_NUMBER", "CREDIT_CARD"]
- config_id: ban_list
banned_words: ["ignore previous instructions", "system prompt"]
```
Set your Guardrails AI API key and restart:
```bash theme={"theme":{"light":"github-light","dark":"github-dark"}}
export GUARDRAILS_API_KEY="grdrls_replace-with-your-guardrails-key"
idun serve
```
On startup, Idun downloads the guardrail validators from the Guardrails AI Hub and initializes them locally. The first start takes 30-60 seconds while models download. Subsequent starts are instant.
Test it by sending a message that contains PII:
```bash theme={"theme":{"light":"github-light","dark":"github-dark"}}
curl -N -X POST http://localhost:8000/agent/run \
-H "Content-Type: application/json" \
-d '{
"threadId": "session-2",
"runId": "run-1",
"state": {},
"messages": [
{"id": "msg-1", "role": "user", "content": "My email is john@company.com and my phone is 555-0123"}
],
"tools": [],
"context": [],
"forwardedProps": {}
}'
```
The request is blocked before it ever reaches your agent. The PII guardrail detected an email address and phone number in the input.
Idun supports 15 guardrail types: PII detection, ban lists, toxic language, jailbreak detection, prompt injection, NSFW filtering, bias detection, topic restriction, gibberish detection, competition checks, language validation, code scanning, RAG hallucination detection, Google Model Armor, and custom LLM-based validation.
Add an `observability` section to your `config.yaml`:
```yaml theme={"theme":{"light":"github-light","dark":"github-dark"}}
observability:
- provider: LANGFUSE
enabled: true
config:
host: "https://cloud.langfuse.com"
public_key: "pk-lf-replace-with-your-public-key"
secret_key: "sk-lf-replace-with-your-secret-key"
run_name: "production-chatbot"
```
Restart the server. Every invocation now shows up in your Langfuse dashboard with full traces: LLM calls, token counts, latencies, tool executions.
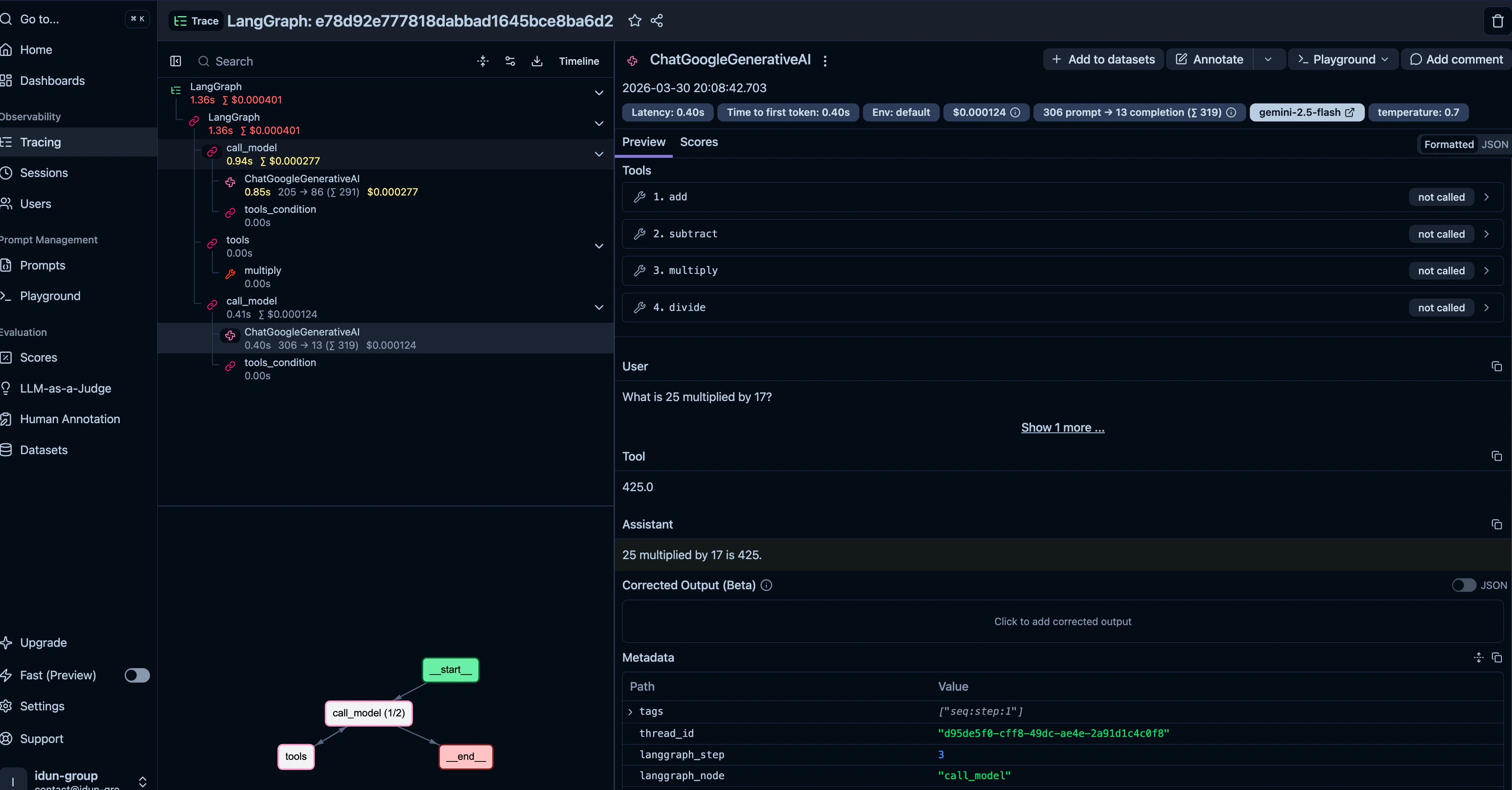 Idun supports five observability providers, and you can attach more than one to the same agent:
| Provider | Mechanism |
| ----------------- | ----------------------------- |
| Langfuse | LangChain callback handler |
| Arize Phoenix | OpenTelemetry + OpenInference |
| LangSmith | LangChain callback handler |
| GCP Cloud Trace | OpenTelemetry span exporter |
| GCP Cloud Logging | Python logging integration |
The engine fans spans out to every enabled provider; each is lazy-loaded. Independently, the local trace store at `/admin/traces/` always captures every run alongside any external providers you configure; see [Local trace store](/observability/traces).
In-memory checkpointing loses conversations when the server restarts. For production, switch to PostgreSQL:
```yaml theme={"theme":{"light":"github-light","dark":"github-dark"}}
agent:
type: LANGGRAPH
config:
name: "Production Chatbot"
graph_definition: "./agent/agent.py:workflow"
checkpointer:
type: postgres
db_url: "postgresql://postgres:postgres@localhost:5432/agent_memory"
```
Idun handles the async connection pool, table creation, and lifecycle management. Your agent code does not change.
For a simpler persistence option, use SQLite:
```yaml theme={"theme":{"light":"github-light","dark":"github-dark"}}
checkpointer:
type: sqlite
db_url: "sqlite:///conversations.db"
```
The `/agent/run` endpoint implements the AG-UI protocol, which is natively supported by CopilotKit and compatible with any SSE-consuming frontend. The standalone also ships its own chat UI at `/`, so you can demo and dogfood without writing one. Replace the bundled UI by pointing `IDUN_UI_DIR` at your own static export; see [Customizing the chat UI](/standalone/customizing-ui).
## Full config.yaml
Here is the complete config file with everything from this guide: agent, guardrails, observability, and PostgreSQL memory. Copy it and adjust the values for your setup.
```yaml config.yaml theme={"theme":{"light":"github-light","dark":"github-dark"}}
agent:
type: LANGGRAPH
config:
name: "Production Chatbot"
graph_definition: "./agent/agent.py:workflow"
checkpointer:
type: postgres
db_url: "postgresql://postgres:postgres@localhost:5432/agent_memory"
guardrails:
input:
- config_id: detect_pii
pii_entities: ["EMAIL_ADDRESS", "PHONE_NUMBER", "CREDIT_CARD"]
- config_id: ban_list
banned_words: ["ignore previous instructions", "system prompt"]
observability:
- provider: LANGFUSE
enabled: true
config:
host: "https://cloud.langfuse.com"
public_key: "pk-lf-replace-with-your-public-key"
secret_key: "sk-lf-replace-with-your-secret-key"
run_name: "production-chatbot"
```
## How Idun compares to alternatives
| Capability | Manual FastAPI | LangServe (deprecated) | LangGraph Platform | Idun Engine |
| -------------------- | -------------- | ---------------------- | -------------------------- | --------------------------- |
| API serving | You build it | Provided | Provided (cloud) | Provided (self-hosted) |
| AG-UI streaming | You build it | Not supported | Not supported | Built in |
| Guardrails | You build it | Not supported | Not supported | 15 types, YAML config |
| Observability | You build it | Limited | LangSmith only | 5 providers, simultaneous |
| Memory/checkpointing | You wire it | Limited | Built in | YAML config, 3 backends |
| MCP tool servers | You build it | Not supported | Not supported | YAML config |
| SSO/OIDC | You build it | Not supported | Cloud-managed | YAML config |
| Vendor lock-in | None | LangChain ecosystem | LangSmith account required | None (open source, GPL-3.0) |
| Self-hosted | Yes | Yes | No (cloud only) | Yes |
Idun Engine is open source and self-hosted. Your agent code stays yours. The config file is the only coupling, and it is a plain YAML file you can generate from any tool.
## Next steps
You now have a production LangGraph agent with streaming, memory, guardrails, and observability. From here:
to give your agent access to external tools via the Model Context Protocol. Add an `mcp_servers` section to your config, or use the admin panel at `/admin/mcp/`.
to require JWT authentication on all agent endpoints. Add an `sso` section with your OIDC issuer and client ID.
(WhatsApp, Discord, Slack, Google Chat) to expose your agent on external channels. Each is a config section with provider credentials, or a card at `/admin/integrations/`.
with versioning and Jinja2 variables through the admin panel at `/admin/prompts/` or in your YAML.
The full configuration reference is at [/configuration](/configuration). The complete list of guardrail types is at [/guardrails/reference](/guardrails/reference).
Idun supports five observability providers, and you can attach more than one to the same agent:
| Provider | Mechanism |
| ----------------- | ----------------------------- |
| Langfuse | LangChain callback handler |
| Arize Phoenix | OpenTelemetry + OpenInference |
| LangSmith | LangChain callback handler |
| GCP Cloud Trace | OpenTelemetry span exporter |
| GCP Cloud Logging | Python logging integration |
The engine fans spans out to every enabled provider; each is lazy-loaded. Independently, the local trace store at `/admin/traces/` always captures every run alongside any external providers you configure; see [Local trace store](/observability/traces).
In-memory checkpointing loses conversations when the server restarts. For production, switch to PostgreSQL:
```yaml theme={"theme":{"light":"github-light","dark":"github-dark"}}
agent:
type: LANGGRAPH
config:
name: "Production Chatbot"
graph_definition: "./agent/agent.py:workflow"
checkpointer:
type: postgres
db_url: "postgresql://postgres:postgres@localhost:5432/agent_memory"
```
Idun handles the async connection pool, table creation, and lifecycle management. Your agent code does not change.
For a simpler persistence option, use SQLite:
```yaml theme={"theme":{"light":"github-light","dark":"github-dark"}}
checkpointer:
type: sqlite
db_url: "sqlite:///conversations.db"
```
The `/agent/run` endpoint implements the AG-UI protocol, which is natively supported by CopilotKit and compatible with any SSE-consuming frontend. The standalone also ships its own chat UI at `/`, so you can demo and dogfood without writing one. Replace the bundled UI by pointing `IDUN_UI_DIR` at your own static export; see [Customizing the chat UI](/standalone/customizing-ui).
## Full config.yaml
Here is the complete config file with everything from this guide: agent, guardrails, observability, and PostgreSQL memory. Copy it and adjust the values for your setup.
```yaml config.yaml theme={"theme":{"light":"github-light","dark":"github-dark"}}
agent:
type: LANGGRAPH
config:
name: "Production Chatbot"
graph_definition: "./agent/agent.py:workflow"
checkpointer:
type: postgres
db_url: "postgresql://postgres:postgres@localhost:5432/agent_memory"
guardrails:
input:
- config_id: detect_pii
pii_entities: ["EMAIL_ADDRESS", "PHONE_NUMBER", "CREDIT_CARD"]
- config_id: ban_list
banned_words: ["ignore previous instructions", "system prompt"]
observability:
- provider: LANGFUSE
enabled: true
config:
host: "https://cloud.langfuse.com"
public_key: "pk-lf-replace-with-your-public-key"
secret_key: "sk-lf-replace-with-your-secret-key"
run_name: "production-chatbot"
```
## How Idun compares to alternatives
| Capability | Manual FastAPI | LangServe (deprecated) | LangGraph Platform | Idun Engine |
| -------------------- | -------------- | ---------------------- | -------------------------- | --------------------------- |
| API serving | You build it | Provided | Provided (cloud) | Provided (self-hosted) |
| AG-UI streaming | You build it | Not supported | Not supported | Built in |
| Guardrails | You build it | Not supported | Not supported | 15 types, YAML config |
| Observability | You build it | Limited | LangSmith only | 5 providers, simultaneous |
| Memory/checkpointing | You wire it | Limited | Built in | YAML config, 3 backends |
| MCP tool servers | You build it | Not supported | Not supported | YAML config |
| SSO/OIDC | You build it | Not supported | Cloud-managed | YAML config |
| Vendor lock-in | None | LangChain ecosystem | LangSmith account required | None (open source, GPL-3.0) |
| Self-hosted | Yes | Yes | No (cloud only) | Yes |
Idun Engine is open source and self-hosted. Your agent code stays yours. The config file is the only coupling, and it is a plain YAML file you can generate from any tool.
## Next steps
You now have a production LangGraph agent with streaming, memory, guardrails, and observability. From here:
to give your agent access to external tools via the Model Context Protocol. Add an `mcp_servers` section to your config, or use the admin panel at `/admin/mcp/`.
to require JWT authentication on all agent endpoints. Add an `sso` section with your OIDC issuer and client ID.
(WhatsApp, Discord, Slack, Google Chat) to expose your agent on external channels. Each is a config section with provider credentials, or a card at `/admin/integrations/`.
with versioning and Jinja2 variables through the admin panel at `/admin/prompts/` or in your YAML.
The full configuration reference is at [/configuration](/configuration). The complete list of guardrail types is at [/guardrails/reference](/guardrails/reference).